Réseaux de Neurones
Principe des Réseaux de Neurones
Les réseaux de neurones sont des systèmes permettant de modéliser, sous forme de couches successives de traitement de données, les transformations appliquées à une donnée en entrée pour obtenir une donnée en sortie, qui est en général une classe (dans la plupart des cas, on cherche à utiliser un réseau de neurones comme un classifieur, fournissant soit la probabilité d’être dans chacune des classes existantes, soit directement la classe prédite).
Comme nous l’avons vu précédemment, la donnée en entrée peut être modélisée sous forme d’un vecteur X décrivant ses caractéristiques (dans notre cas, les X1..Xn sont donc les variables ou features décrivant le cheval). Chaque feature correspond alors à 1 neurone, et ceux-ci forment donc la couche d’entrée de notre réseau, composée de n neurones.
Dans le cas d’une classification binaire (par exemple, gagnant/pas gagnant pour le cas de nos courses de chevaux), la sortie est alors soit 0 soit 1, on a alors 1 neurone en sortie.
Si on cherchait à prédire la place parmi les 6 catégories suivantes: 1er, 2ème, 3ème, 4ème, 5ème ou bien place supérieure à 5), alors on aurait 6 neurones en sortie de notre réseau.
Entre la couche d’entrée et de sortie, les réseaux de neurones contiennent des couches intermédiaires, appelées « couches cachées ». Le nombre de ces couches et leur taille (nombre de neurones) correspondent à des choix de modélisation.
Dans le cas des réseaux à couches Fully Connected, chaque neurone de chaque couche est relié à chaque neurone de la couche précédente et de la couche suivante.
Chaque neurone transporte donc une « part » de l’information fournie par les neurones de la couche d’entrée et transmise de couche en couche, et cette part est déterminée par un poids (ou coefficient synaptique) que l’on affecte sur chacune des connexions entre chaque neurone. Un neurone donné reçoit donc une somme pondérée des informations transmises par les neurones de la couche précédente. Une fonction d’activation vient alors s’appliquer à cette somme pondérée, pour déterminer la sortie exacte de ce neurone:
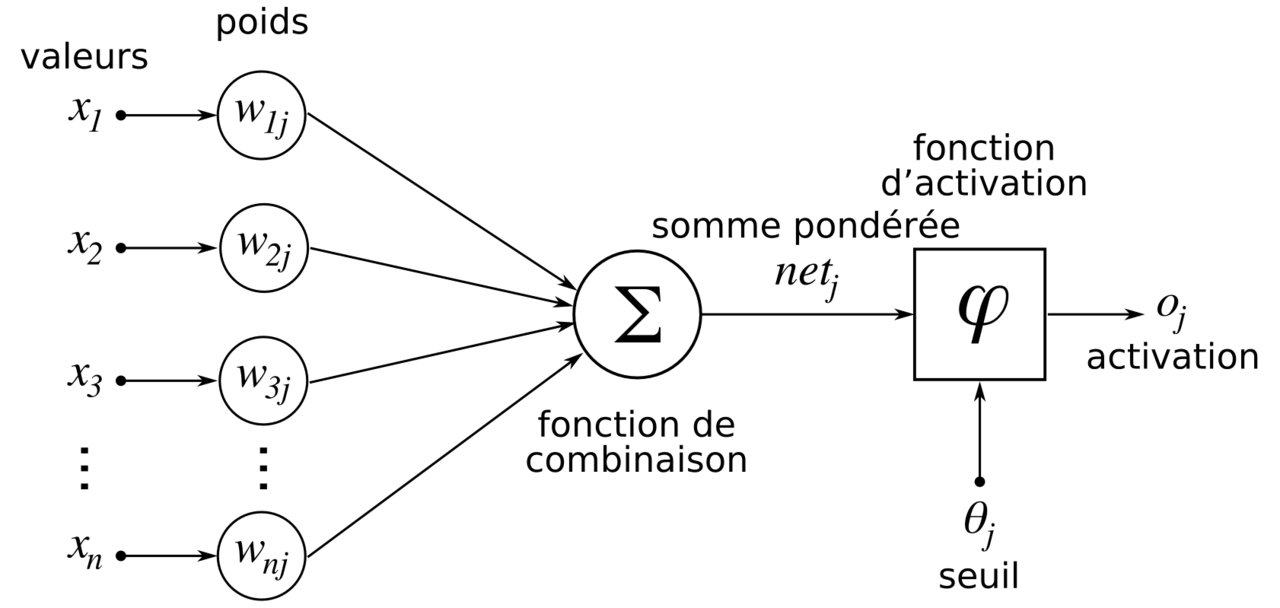
L’apprentissage de notre modèle va consister à adapter les poids de notre réseau, à chaque fois qu’on présente une donnée (exemple un cheval) de notre dataset d’apprentissage.
Cette adaptation se fait de façon à minimiser l’erreur faite entre la donnée en sortie (la classe prédite ou bien la probabilité d’être dans cette classe), et la classe réelle (dans notre cas, « gagnant » ou « pas gagnant »), selon un algorithme précis (rétro-propagation du gradient, que nous ne détaillerons pas ici, mais qui permet, depuis l’erreur calculée au niveau de la couche de sortie, de la rétro-propager sur chacune des connexions, de proche en proche jusqu’à remonter à la couche d’entrée).
Plus on présente de données au réseau dans l’apprentissage, et plus les poids vont être ajustés de manière à optimiser son taux de bonne classification, ce qui revient dans notre cas à prédire au mieux la classe de notre cheval, lorsqu’on lui présente les caractéristiques de ce cheval.

Cette modélisation est ainsi nommée par analogie avec le fonctionnement du cerveau humain (qui l’a inspirée), constitué de neurones reliés entre eux par des synapses et via lesquelles ils se transmettent des informations qui vont activer ou non le neurone suivant, selon l’importance de l’information totale reçue par le neurone.
L’avantage de cette modélisation (comparée à celle offerte par des algorithmes plus « standards » comme les SVM vus précédemment) est qu’il est possible de créer une infinité de réseaux, en jouant sur le nombre de couches, leur taille (nombre de neurones à chaque couche), et les fonctions d’activation. Celles-ci peuvent être non linéaires ce qui permet de prendre en compte la non-linéarité potentielle de la problématique qu’on traite. On peut donc créer des modèles personnalisés aussi complexes qu’on le souhaite, pouvant coller au plus près de notre distribution de données et de notre problématique, pour peu qu’on définisse un « bon » réseau, ce qui est la difficulté principale de l’exercice, très chronophage de par son temps de traitement mais aussi de par le nombre de réseaux potentiellement important qu’on va essayer.
On parle aussi de Deep learning lorsqu’on parle de réseaux de neurones et que ceux-ci utilisent un nombre important de couches cachées (on a alors un réseau « profond »).
Ce concept date des années 1940 mais ne prend réellement son essort que dans les années 2000, avec l’accroissement des capacités de calcul, celles-ci devant être importantes pour le Deep learning étant donné le nombre d’opérations à réaliser, pouvant être gigantesque.
Les réseaux de neurones reposant sur des calculs matriciels (puisque sollicitant majoritairement des calculs linéaires successifs mais très nombreux sur un vecteur d’entrée), l’apport de la technologie des cartes graphiques (GPU, qui effectuent de façon similaire des transformations complexes sur les pixels représentés par des vecteurs) et des processeurs multi-coeurs (permettant d’effectuer des opérations en parallèle) est primordial dans les avancées réalisées par le Deep learning.
Les principales applications de ce domaine sont aujourd’hui le traitement du texte et du langage (Natural Language Processing, ou deep text) et la reconnaissance d’image (Computer Vision).
Implémentation dans Python
Nous utilisons Keras (bibliothèque de Python), qui est une sorte de surcouche offrant une ergonomie aidant à aller plus vite dans l’implémentation du réseau de neurones (en comparaison à Pytorch par exemple), en faisant appel directement à Tensorflow (librairie d’algorithmes de AI/ML), ce qui permet de simplifier le code et de se concentrer sur les données et les méthodes.
Comme pour SVM nous devons présenter en entrée du réseau des données normalisées, nous effectuons donc au préalable les mêmes transformations sur les données numériques (scaling) et sur les données catégorielles (via Onehotencoder).
Un point important à noter dans ces transformations, est qu’il faut appliquer les mêmes transformations sur les données de test, que sur les données d’apprentissage. Ainsi les paramètres de scaling et de Onehotencoder doivent être sauvegardés lors de la phase d’apprentissage (en utilisant pickle.dump), pour être appliqués de la même façon sur les données de test (en utilisant pickle.load), sinon l’évaluation est faussée: le scaling s’il est refait sur les données de test sera différent, et la transformation Onehotencoder pourrait potentiellement être faite sur un nombre différent de colonnes – en général inférieur – si on a un nombre de valeurs de variables catégorielles différent entre les données de test et les données d’apprentissage. Pour utiliser ce réseau sur de nouveaux vecteurs d’entrée (nouveaux chevaux) il faudra donc également appliquer ces mêmes transformations au préalable.
Ceci garantit que le nombre de features de notre réseau de neurones sera bien fixe en apprentissage, validation et utilisation, ce qui est indispensable puisque nous devons fixer le nombre de neurones de chaque couche de notre réseau et en particulier de la couche d’entrée, dont le nombre de neurones doit être égal au nombre de features.
Définition du réseau
Comme nous venons de le voir le nombre de neurones de la couche d’entrée est déterminé par le nombre de features formant le vecteur qui décrit les caractéristiques du cheval, après transformation.
Nous devons ensuite déterminer le nombre et la taille des couches cachées.
Pour ne pas utiliser un réseau trop complexe à ce stade et éviter l’overfitting, nous choisissons ici d’utiliser 3 couches cachées. Nous utiliserons des couches de type Dense (Fully Connected), ce qui signifie que tous les neurones de ces couches sont connectés à tous ceux de la couche précédente.
Il faut maintenant fixer la taille des couches.
Certaines recommandations existent pour la taille de la 1ère couche cachée, par exemple que celle-ci:
- soit égale à celle de la couche d’entrée (Wierenga et Kluytmans, 1994)
- soit égale à 75% de celle-ci (Venugopal et Baets, 1994)
- soit égale à la racine carrée du produit du nombre de neurones dans la couche d’entrée et de sortie (Shepard, 1990)
Nous choisissons ici de la fixer égale à la taille de la couche d’entrée.
De façon arbitraire nous choisissons ensuite de fixer la taille de la 2ème couche cachée à la moitié de la taille de la 1ère couche, et la taille de la 3ème à la moitié de la taille de la 2ème couche (on prend à chaque fois les partie entières pour avoir un nombre entier de neurones).
La taille de la couche de sortie est déterminée par le nombre de classes que nous souhaitons avoir en sortie.
Ici, comme nous voulons avoir un résultat binaire, un seul neurone renvoyant un résultat entre 0 et 1 est nécessaire, la couche de sortie est donc de taille 1.
Les fonctions d’activation utilisées sont des fonctions Relu pour les couches cachées, et on utilise une fonction sigmoïde sur la couche de sortie, pour obtenir un résultat entre 0 et 1.
Après chaque couche cachée, nous pouvons choisir de paramétrer un taux de Dropout, qui va permettre d’ « éteindre » aléatoirement certains neurones pour les « oublier » dans l’apprentissage, de manière à éviter l’overfitting.
On fixe ici de taux de Dropout à 10% pour chaque couche cachée.
L’architecture étant définie, il nous reste à fixer:
- la fonction de perte, utilisée pour calculer la perte entre la valeur réelle et la valeur prédite, et ajuster ensuite les poids du réseau: étant dans un cas de classification binaire, nous utilisons ici binary_crossentropy
- les hyperparamètres du réseau, les principaux étant:
– batch_size qui fixe la taille des batchs
– epochs qui fixe le nombre d’itérations
– l’optimizer
Pour choisir la combinaison la plus pertinente d’hyperparamètres, nous pouvons utiliser gridsearchCV, qui va tester toutes les combinaisons de paramètres parmi les valeurs fournies, et que nous fixons ici à:
params = {
‘batch_size’:[10,20,50,100],
‘epochs’:[5,10,20,50,100],
‘optimizer’:[‘SGD’, ‘RMSprop’, ‘Adagrad’, ‘Adadelta’, ‘Adam’, ‘Adamax’, ‘Nadam’]} - la métrique (score) permettant d’évaluer la performance du réseau: nous choisissons ici de façon classique la métrique « accuracy »
- des options dans l’apprentissage, comme Earlystopping qui permet d’arrêter l’apprentissage si après un certain nombre d’itérations successives le score ne s’améliore pas (ou bien, la perte ne diminue pas).
On fixe ce nombre d’itérations à l’aide de la valeur patience.
Ainsi en définissant patience=5 par exemple, si après la 30ème epoch le score ne s’est pas amélioré lors des epoch 31 à 35, l’apprentissage s’arrête, sans aller au bout du nombre d’epochs paramétré, ce qui permet de réduire le temps de traitement et également d’éviter l’overfitting.
Comme pour SVM, nous avons la possibilité de travailler directement sur une fraction du dataset, ou bien sur un dataset équilibré à 50% gagnants et 50% de non gagnants, ou bien sur un dataset rééquilibré avec le paramètre class_weights.
On s’aperçoit comme pour SVM qu’en travaillant sur un dataset non équilibré, on obtient ici aussi une classification systématique dans la classe 0 (non gagnant), mis en évidence par les matrices de confusion.
On va donc ici aussi travailler sur les datasets rééquilibrés, selon les 2 méthodes déjà vues pour SVM.
Nous effectuerons les calculs sur Google Colab afin de bénéficier de la GPU (contrairement à SVM qui n’utilise pas les ressources GPU, pour les réseaux de neurones on observe des temps de calculs bien meilleurs avec GPU que sur un PC individuel équipé seulement de CPU).
Résultats méthode 1 – dataset équilibré à 50-50
A noter que pour le choix des hyperparamètres, un trop grand nombre de combinaisons à tester peut entraîner un message d’erreur lié à une mémoire insuffisante. On peut alors dans ce cas procéder par tatônnement, en testant des combinaisons de paramètres en plusieurs étapes:
- test1:100 epoch and batch size 100, rmsprop and adam => meilleurs paramètres {‘batch_size’: 100, ‘epochs’: 100, ‘optimizer’: ‘Adam’} => meilleur score 0.6721
- test2:100 epoch and batch size 50, rmsprop and adam => meilleurs paramètres {‘batch_size’: 50, ‘epochs’: 100, ‘optimizer’: ‘Adam’} => meilleur score 0.6714 => un peu moins bien et 2 fois plus de temps (30 min au lieu de 15min) donc on garde batch size 100
- test3: 200 epoch and batch size 100, rmsprop and adam => meilleurs paramètres {‘batch_size’: 100, ‘epochs’: 200, ‘optimizer’: ‘Adam’} => meilleur score 0.6718 => presque pareil et 1h au lieu de 15min donc on garde epoch 100
- test4: 100 epoch and batch size 100, optimizers ‘SGD’, ‘RMSprop’, ‘Adagrad’, ‘Adadelta’, ‘Adam’, ‘Adamax’, ‘Nadam’ => meilleurs hyperparamètres {‘batch_size’: 100, ‘epochs’: 100, ‘optimizer’: ‘SGD’} => meilleur score 0.7277 donc on sélectionne SGD
Au final on retient donc l’optimizer SGD, un batch size de 100 et un nombre d’epochs de 100.
Il peut y avoir une meilleure combinaison de paramètres bien sûr, soit parmi celles du gridsearch que nous n’avons pas pu tester complètement, soit avec des valeurs différentes de epoch et de batch_size (en revanche pour optimizer, le gridsearch initialement souhaité contenait tous les optimizers disponibles).
On peut ensuite appliquer un nouveau gridsearch pour optimiser les paramètres de SGD learning rate et momentum.
On se retrouve au final avec un score restant aux alentours de 72%.
On retrouve donc par ce réseau de neurones un score semblable à celui qu’on avait obtenu avec SVM sur ce dataset.
Nous pouvons ensuite afficher la matrice de confusion, tracer la courbe ROC, faire des tests manuels sur de nouveaux chevaux.
Mais nous restituerons ici ces étapes restantes plutôt pour la méthode 2 (cas du dataset modulé avec class_weights) qui comme nous l’avons expliqué dans la partie SVM, reflètera mieux la réalité de notre problématique de classer une liste de chevaux d’une course (la liste étant par nature déséquilibrée).
Résultats méthode 2 – dataset équilibré avec class_weight
On travaille ici tout d’abord sur une liste réduite de paramètres, pour effectuer la totalité des combinaisons de gridsearch, sans avoir de problème de mémoire:
params = {
‘batch_size’:[10,50,100],
‘epochs’:[50,100],
‘optimizer’:[ ‘RMSprop’,’Adam’,],
}
Nous obtenons les résultats suivants:
![]()
On obtient un score de 87% environ, nous retrouvons là aussi le même score que celui trouvé avec SVM poly sur ce dataset !
Nous pouvons alors réapprendre le modèle avec ces paramètres optimisés, et l’évaluer via les courbes de loss et accuracy:


Ces courbes sont relativement perturbantes.
La courbe d’accuracy nous montre que le modèle apprend bien et arrive à généraliser sur le jeu de test, l’accuracy (score) augmente avec le nombre d’itérations et la valeur finale de 87% est satisfaisante.
Cependant, alors que la loss (calculée via la fonction cross-entropy) diminue bien en apprentissage, elle augmente en test.
Comment interpréter cette augmentation de la loss de test, alors que le score augmente lui aussi dans le même temps?
Nous pouvons faire plusieurs hypothèses à ce stade:
1/ le modèle est en overfitting, il offre trop de flexibilité par rapport à la complexité du problème
2/ L’accuracy va simplement prendre en compte si la classe trouvée (gagnant ou non gagnant) est la bonne, alors que la loss va prendre en compte la valeur/le pourcentage liée à cette prédiction.
Comme évoqué ici, il est donc possible qu’au fil des itérations les classes soient de mieux en mieux prédites (l’accuracy augmente) mais que dans le même temps la certitude de ces prédictions diminue (la loss augmente alors également). Il est également possible à l’inverse, que les classes mal prédites soient de moins en moins nombreuses (l’accuracy augmente), mais que la certitude de cette mauvaise prédiction ait empiré (la loss a donc augmenté).
Il faudra donc essayer d’autres hyperparamètres ou d’autres réseaux pour voir comment ce phénomène évolue et tenter d’avoir un modèle plus stable.
La matrice de confusion quant à elle montre bien que le modèle prédit bien des gagnants et non gagnants:

On lit ici que:
- 4726 chevaux de classe 0 (non gagnant) sont prédits à 0
- 322 chevaux de classe 1 (gagnant) sont prédits à 0
- 339 chevaux de classe 0 (non gagnant) sont prédits à 1
- 76 chevaux de classe 1 (gagnant) sont prédits à 1
Le taux de bonne classification (accuracy) est ici de (4726+76)/(4726+76+339+322)=87,9% avec cette matrice.
Le réseau prédit donc bien les 2 classes (contrairement au réseau sans rééquilibrage de classes) mais il prédit trop de « faux gagnants » (339) par rapport aux « vrais gagnants » (76).
Comme nous l’avons déjà vu pour SVM ceci est visible en calculant d’autres métriques, ce qui est important dans le cas de datasets avec des classes non équilibrées:
- La précision (precision en anglais) est définie par le rapport entre les vrais positifs et la somme des vrais positifs et des faux positifs (elle est donc bien différente de l’accuracy, attention au faux ami en anglais!)
Elle est ici de p=76/(76+339)=18,3% - La métrique de la précision appliquée aux exemples négatifs est de:
4726/(4726+322)=93,6%
Notre modèle prédit donc beaucoup mieux les non gagnants que les gagnants, et le taux de bonne prédiction des gagnants est bien trop faible (18,3% à comparer aux 73% obtenus avec SVM poly).
Là aussi cela met en évidence la nécessité de continuer ces travaux, avec d’autres hyperparamètres et d’autres réseaux, et si possible d’autres métriques que l’accuracy pour l’évaluation du modèle, et notamment la précision (il semble que celle-ci ne soit pas disponible dans Keras, mais on peut la définir manuellement).
On pourra aussi travailler sur l’importance de chaque variable (le poids des features) dans la prédiction, en utilisant des fonctionnalités telles que features_importance (qui toutefois ne semble pas disponible dans Keras).
Le réseau de neurone testé ici performe aussi bien que SVM poly pour classer les chevaux d’un dataset déséquilibré en gagnant ou non gagnant, avec le même taux de bonne classification de 87% pour l’ensemble des chevaux, cependant pour la classification des chevaux gagnants ce taux tombe à 18%, alors qu’il était de 73% pour SVM.
De plus le réseau est assez peu stable comme en témoigne la courbe loss.
Il faudra tester d’autres réseaux et hyperparamètres pour améliorer la stabilité et tenter de surperformer l’algorithme SVM poly.
Bonjour,
Vos articles sont très intéressants, après avoir pris connaissance de la littératures des courses depuis plusieurs années, je fais parti des parieurs qui utilisent l’ IA pour les statistiques.
Pouvez vous m’indiquer comment se procurer les différents outils d’analyse PMU qui se trouvent sur votre site.